[BlueLeaf1336]> PROBLEMS> なぁバーコードを読もうじゃないか>
| history | TOP |
2005/04/02:作成
| 2005/04/02 | TOP |
まず手始めに、CODE-39に手をつける事にします。参考書は、
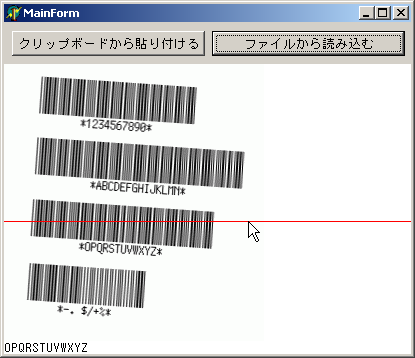
です。また前回のとおり、勉強用のバーコードは、MiBarcode(Windows95/98/Me/文書作成)で作成することとします。当然ですが、背景はまっ白で。バーコードは真っ黒です。
| 都合のよい単純化 | TOP |
少し勉強してみます。そして単純化します。わかりにくいところは無視します。画像も文言も「無断転用、無断転載は禁じます。」に応じてリンクだけとします。しかし、規格を整理したからってなんで、禁じるんだろう。不思議。邪魔くさかったから?
| 基本方針 | TOP |
前回作ったプログラムの前準備データをもとに考えます。前準備データは、サイズ400の1次元配列に、バーコード画像を水平にちょん切った時に(多分斜めになってても関係無いと思う。原理的には)、きった線が通った位置にあるピクセルの並び(たとえば白白白白白黒黒白白黒...)を叩き込んだものです。とりあえず「黒なら1」「白なら0」とします。
この時点では、細い線が何ピクセル(1あるいは0の連続する個数)なのか、太い線が何ピクセルなのか不明です。MiBarcodeでも、横何倍にするかを指定できるわけです。
ややこしいので非常に、否、異常に単純化して、この配列内にバーコードの全てが収まっていて、バーコードの数はたった1つだけとします。つまり配列を最初から読んでいき、最初に見つかった「1」から最後に見つかった「1」までがバーコードの全幅と考えます。また、それぞれ連続する個数を数えていきます。
よくわかりませんが、
000...00011000011001111001111001100....
こういうのがあったときに(左の余白とスタートコードのつもりです。この時点では細線太線の幅は不明とします)、最初の「1(黒)」までの「0(バーコードの左の余白)」を読み捨てて、同様に最後の「1」以降の「0」も読み捨てます。つまり、
11000011001111001111001100....
こうします。で、次に「1なら1」「0なら0」のくり返している数を数えていきます。
2422424222....
こんな感じに。この時点でどれが黒でどれが白かについての情報を捨ててしまったような気がしてどきどきしますが、実際には黒から始まり白黒白とくり返しているハズなので問題なしです。多分。
それから、この時点で細線の太さ・太線の太さがわかります。なぜなら、CODE-39ではスタートコードが必ずあって、このスタートコードは「*」で「*」は「細太細細太細太細細」だから、最初の2つを眺めれば後はそれが使われているはずだからです。また、細と太の比率もわかります。でもまぁ比率よりも、1番目に近いほうが細くて、2番目に近いほうが太いということでよさそうな感じがします。
で、2種類の数字しかないことを祈りながら、全体を眺めます。2種類とは小さめと大きめです。もちろん「小さめは細線」「大きめは太線」に対応します。調べた結果を更に配列に作ります。大きめなら「#」小さめなら「|」とします。
|#||#|#|||....
こんな感じです。もう少しです。あ、その前に、この「#と|からなる文字列」の文字数が「9の倍数」でないと駄目です。1文字は5個の黒と4個の白から作られるらしいので。また、6個の細と3個の太から作られることから、「|」の数は「6の倍数」「#」の数は「3の倍数」のはずです。
違います。文字と文字の間に隙間(|)があるのでそうはなりません。
文字は3個の「#」と6個の「|」で構成されていて、隙間「|」をつけるとちょうど10個になります。ただし、最後の文字については、それ以上右側に隙間は必要ないので、逆に考えると無理やり最後の文字にも隙間を付け加えてやると、全ての「#と|」の数は10の倍数になるはずです。また、それを10で割ってやれば文字数も得られます。
こんなやり方、へぼすぎる気がしますが、くじけずに前へ進みます。
やっと、文字とパターンの対応表を使うときが来ました。邪魔くさいんですが、頑張ることにして、「#と|たち」と「文字」に関する変換表を作ります。
| 文字 | パターン | 文字 | パターン |
|---|---|---|---|
| 1 | #||#||||# | M | #|#||||#| |
| 2 | ||##||||# | N | ||||#||## |
| 3 | #|##||||| | O | #|||#||#| |
| 4 | |||##|||# | P | ||#|#||#| |
| 5 | #||##|||| | Q | ||||||### |
| 6 | ||###|||| | R | #|||||##| |
| 7 | |||#||#|# | S | ||#|||##| |
| 8 | #||#||#|| | T | ||||#|##| |
| 9 | ||##||#|| | U | ##||||||# |
| 0 | |||##|#|| | V | |##|||||# |
| A | #||||#||# | W | ###|||||| |
| B | ||#||#||# | X | |#||#|||# |
| C | #|#||#||| | Y | ##||#|||| |
| D | ||||##||# | Z | |##|#|||| |
| E | #|||##||| | - | |#||||#|# |
| F | ||#|##||| | . | ##||||#|| |
| G | |||||##|# | Space | |##|||#|| |
| H | #||||##|| | * | |#||#|#|| |
| I | ||#||##|| | $ | |#|#|#||| |
| J | ||||###|| | / | |#|#|||#| |
| K | #||||||## | + | |#|||#|#| |
| L | ||#||||## | % | |||#|#|#| |
こんなの。えー、作った文字列を先頭から9文字ずつ取り出してどの文字に対応するかを調べて置き換えていけば完了です。遅そうです。この方法は止めましょう。
素直に、「#=1」「|=0」と考えて「0と1の並び」にして2進数のつもりで数字に直す。コレだともう少しましな気がしてきました。少なくとも変換表からコード化されている文字を探すのが。
| 文字 | 並び | 10進数換算 | 文字 | 並び | 10進数換算 |
|---|---|---|---|---|---|
| 1 | 100100001 | 289 | M | 101000010 | 322 |
| 2 | 001100001 | 97 | N | 000010011 | 19 |
| 3 | 101100000 | 352 | O | 100010010 | 274 |
| 4 | 000110001 | 49 | P | 001010010 | 82 |
| 5 | 100110000 | 304 | Q | 000000111 | 7 |
| 6 | 001110000 | 112 | R | 100000110 | 262 |
| 7 | 000100101 | 37 | S | 001000110 | 70 |
| 8 | 100100100 | 292 | T | 000010110 | 22 |
| 9 | 001100100 | 100 | U | 110000001 | 385 |
| 0 | 000110100 | 52 | V | 011000001 | 193 |
| A | 100001001 | 265 | W | 111000000 | 448 |
| B | 001001001 | 73 | X | 010010001 | 145 |
| C | 101001000 | 328 | Y | 110010000 | 400 |
| D | 000011001 | 25 | Z | 011010000 | 208 |
| E | 100011000 | 280 | - | 010000101 | 133 |
| F | 001011000 | 88 | . | 110000100 | 388 |
| G | 000001101 | 13 | Space | 011000100 | 196 |
| H | 100001100 | 268 | * | 010010100 | 148 |
| I | 001001100 | 76 | $ | 010101000 | 168 |
| J | 000011100 | 28 | / | 010100010 | 162 |
| K | 100000011 | 259 | + | 010001010 | 138 |
| L | 001000011 | 67 | % | 000101010 | 42 |
目がすごく痛いです。これで間違ってたら...
| 攻略? | TOP |
できたような感じです。チェックデジットに付いては完全に無視しています。どうせついててもそれがチェックデジットかどうかを判定することができそうもない(調べてもないですが)ので、無視です。
まず、MiBarcodeが作ったそのままなら大丈夫そうです。で下の図は、IrfanViewを使用して、数度だけ傾けたものです。回転しきってないところなのかもしれませんが、ホットスポットを見つけることができれば読めているようです。さすが、300万分の1の誤読率です(このプログラムじゃあないです。CODE39がです)。
拡大や縮小をすると判定できなくなります。実は、細線太線の比率とかすごく微妙でどうやったらそこそこ読めるようになるのかわからなかったので滅茶苦茶書いてます。それが原因のような気もしますが、とりあえず80%縮小や120%拡大したらアウトでした。
で、実行ファイルとソースコードです。わやくちゃですが、このページの上の方で書いた方針通りにそのまま作っています。テストに使用したバーコード画像も同梱しています。少しだけ楽しいです。
20050402NaBaRead.zip(250,411bytes)(74,359bytes)
根本的に、横1直線上で判定しているので、傾いたら傾いたなりに追いかけるといったことはできません。やっぱりハードウェアのバーコードリーダの自由度の高さって無敵です。まさに自由自在。
とにかくCODE39は攻略したことにします。次は別のコードといきたいところですが、もともとの動機は、(あまりに無謀ですが)
この記事の
...『QuickTime』(クイックタイム)対応のデジタルビデオカメラで製品のバーコードを読み込み、読み込んだバーコードを使って製品の詳細情報をインターネットからダウンロードできる機能...
の部分です。ビデオカメラから読み込んだ(どう考えてもすごく粗そうな)動画を元に、バーコードを読み取るなんてできるのか、というわけです。実際その辺のスーパーでも、グニャグニャ曲がったパンの包装紙のバーコード読めてるわけだからできるんだろうけども、なんかかっこいいと思ったわけで。
まぁそれ以前に、このプログラムを作っているパソコンには動画を取り込む機能もないし、取り込むためのプログラムを作ることもできそうにないですが。話はそれましたが、ひょっとしたらこの無謀な方に手を出して、奇跡的に(自分で全部やるかどうかは全く別として)動画に表示されたバーコードをプログラムで読めるような環境が作れたとして、書籍のバーコードがCODE39じゃないことに気づいて嫌になる方を選ぶような気もします。
| EOF | TOP |