[BlueLeaf1336]> PROBLEMS> パターン認識への長い道のり>
| history | TOP |
2006/04/23:作成
| 2006/04/23 | TOP |
二つのサイズの同じグレースケールの画像が似ているかどうかを評価します。ただこういうときのセオリーを知らないので、テキスト(C言語による画像処理入門 昭晃堂)のシンプルな方法をさらに手を抜いて真似します。
「シンプルな方法」とは、二つの画像の各ピクセルの階調値(256色グレースケールなので各ピクセルは 0 ~ 255 の間の値)の差分をとって、どんどん加算していきます。まったく同じ階調値であれば、差分は 0 となるので、完全に同じ二つの画像を比べると、この差分の合計は 0 になります。逆にこの合計値が大きければ大きいほど二つの画像は似ていない、と判定しようと、そういう方法です。
「さらに手を抜いて」というのは、テキストでは、あまりに平坦な画像は評価を下げるということをやっているんですが、今のところはその処理をはつっています。
| 実行結果 | TOP |
TestMatch.zip(189,211Bytes) ソースコードと実行ファイルです。画像ファイルをフォームに抱え込んでいるので、えらくサイズがでかくなってますが、中身のほうはサイズに比例してません。
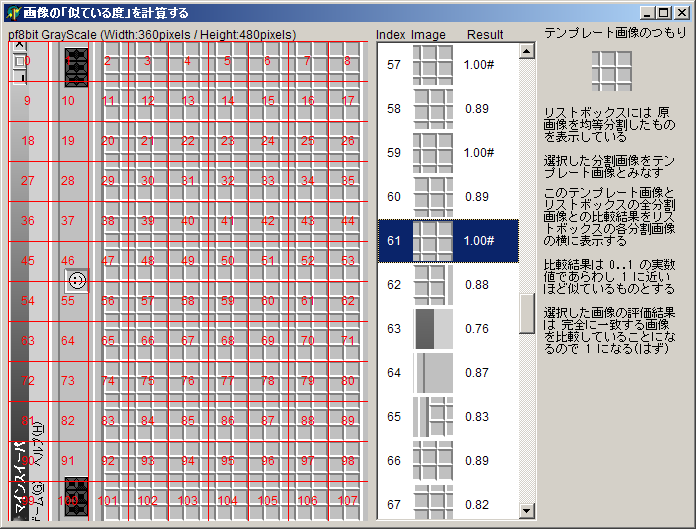
よくわからない実行結果ですが、未来の自分のために簡単に説明しておくと、「似たような画像をたくさん集める」代わりにマインスイーパの実行画面をそのままキャプチャして代用しています。この画像を幅40×高40の108個に分割してそこそこ似ている画像を108個準備したつもりとしています。
次に、分割した画像をリストボックスにばらして描画しています。このリストボックスには、全体の画像を分割した時のインデックスと、その分割画像そのものと、比較元の画像との評価結果を描画しています。
評価結果は、1に近いほど比較元の画像と似ているように調整した諧調値の差分の合計で表現しています。
ここで、「比較元の画像」として、分割画像のどれかひとつで代用しています。当然、比較元の画像とした分割画像は、評価結果が 1 (完全一致) になるはずで、そこそこ似ている分割画像には、そこそこ 1 に近い評価結果になってほしく、あまりにていない分割画像は、それなりに 0 に近くなってほしいわけです。
たとえば、人間が見ると、図の 60 と 61 はかなり似ているわけですが、この比較方法ではあまり似ていない感じに評価されています。極端に言えば、1ピクセルずらしただけの画像二つがほとんど似ていないと評価されてしまう可能性もあります。
このあたりは、テキストでは、比較元の画像を平坦化することで回避してい(るように思え)ます。
それはそれとして、大体思ったとおりの評価結果になっているようなので、とりあえずテストは成功とします。でも、実際には比較元だけではなく原画像のほうも比較範囲を取り出した跡でそれなりに平坦化すべきかも知れません。この比較方法の調整がパターン認識の醍醐味のような気がしなくもないです。
| EOF | TOP |