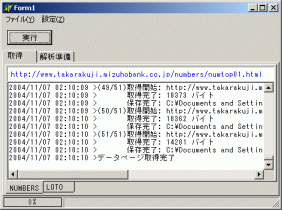
 前回作成済みの「NUMBERS当選番号取得」実行状況です。ただし、ボタンの置き場所を思いつかなかったため、ページコントロールを入れ子にしています。
前回作成済みの「NUMBERS当選番号取得」実行状況です。ただし、ボタンの置き場所を思いつかなかったため、ページコントロールを入れ子にしています。「LOTO当選番号取得」は(何故か)画面の下に配置したタブを切り替えるとできます。同じく前回作成済みです。
実行結果は一切変わっていません。
[BlueLeaf1336]> PROBLEMS> MizuhoGetter>
| history | TOP |
2004/11/06:作成
| 2004/11/06 | TOP |
前回書いたとおり、取得したHTMLのソースコードを解析します。基本的に一定のルールにフォーマットにしたがって、データが配置されていると信じます。
上のリンクを参考に、正規表現を使って、取得したオリジナルのファイルを加工して、そこからは個別(7種類あるのでそれぞれべた書きのヘナチョコな方法で)解析していきます。
まずは、HTMLソースコードの加工です。手順は次のようにやろうと思います。
コレだけやっておけば、個別解析が楽になるんじゃないかと。それに、上記の加工処理はファイルのフォーマットに制限されずにやってしまえるので、先にやっておこうかと。
実際に使用した正規表現のパターンは次のようになりました。
| 処理 | パターン | 置換後の文字列 |
|---|---|---|
| HTMLタグ除去 | '<!--(.|\n)*-->|<[^>]*>' | '' |
| 空白・空行除去 | '\s*('#13#10')+\s*' | #13#10 |
HTMLタグ除去については、第IV部〜テキスト編集を極める!! 正規表現についてにあったパターンをそのまま使用させていただきました。
空白・空行除去については、脳内妄想で試行錯誤して(少なくとも今回対象にするHTMLファイルに対しては)うまくいくことが確認できたものです。Visual Basic Scripting Edition Pattern プロパティによると、「\s」=「スペース、タブ、フォームフィードなどの任意の空白文字と一致します。」、「*」=「直前の文字と 0 回以上一致します。」、「+」=「直前の文字と 1 回以上一致します。」なので、日本語で書くと「連続する空白(なくても可)+改行(1回以上)+連続する空白(なくても可) => 改行1つ に置き換える」ということです。
単に複数の改行を1つの改行に置き換えるだけで、空白行が除去できるわけですが、ここでは右トリム・空行除去・左トリムを同時にやろうとしているだけです。※実際にはもうちょっとヘンなことをやってますが、主なものは上記2つです。
| スクリーンショット | TOP |
前回作成済みの「NUMBERS当選番号取得」実行状況です。ただし、ボタンの置き場所を思いつかなかったため、ページコントロールを入れ子にしています。
「LOTO当選番号取得」は(何故か)画面の下に配置したタブを切り替えるとできます。同じく前回作成済みです。
実行結果は一切変わっていません。
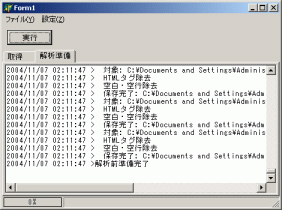 今回作成したタグ除去・空白除去処理中の画面です。別に楽しくも何ともないです。
今回作成したタグ除去・空白除去処理中の画面です。別に楽しくも何ともないです。
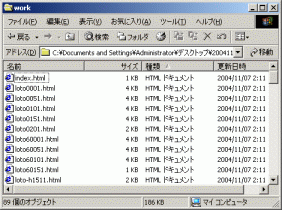 前処理完了結果。生のデータに比べて、圧倒的にサイズが減っています。かなり嬉しくなります。
前処理完了結果。生のデータに比べて、圧倒的にサイズが減っています。かなり嬉しくなります。
20041106MizuhoGetter.zip(12,088bytes)※ソースコードと実行ファイル。
「HTMLソースの解析」と名乗りながら、解析は一切していません。アホすぎるスクリーンショット貼り付けにより、またもや次のページへ繰り越しです。次回こそは、(少なくとも1つのフォーマットぐらい)解析したいところです。
| EOF | TOP |